The Evolution of Robot Learning: Insights and Future Directions
Written on

This article serves as a companion piece to my forthcoming presentation at Nvidia GTC, infused with personal insights. The views expressed are solely my own and do not represent Google DeepMind or the diverse perspectives of my colleagues.
The atmosphere at the latest Conference on Robot Learning, held six months ago in Atlanta as of this writing, felt distinctly transformative compared to previous years. A palpable sense of progress was evident, as many presentations highlighted robotic systems that actually demonstrated functionality—albeit within specific academic criteria of success. Where the community once grappled with basic tasks like stacking colored blocks, we are now witnessing genuine advancements in tackling intricate, real-world challenges.
I often jest that a research career entails a commitment to a lifetime of addressing issues that remain unresolved. During informal discussions between sessions, researchers were left pondering the question, “Now what?” This wasn't due to a sense of having achieved a definitive success, but rather an acknowledgment that the pace of innovation in robotics has picked up, necessitating a reassessment of our research trajectories and methodologies.
How did we arrive at this juncture? As with many developments in AI, we can trace this evolution back to the emergence of GPT and the rise of modern large language models (LLMs) around 2021. Suddenly, extraordinary reasoning capabilities became accessible to many, leading to discussions about the nearing reality of artificial general intelligence (AGI). Concurrently, the field of robotics, often referred to as "Embodied AI," was expected to be the key to achieving AGI, providing real-world grounding and commonsense reasoning. The sudden prominence of “Language Modeling,” a subfield previously overlooked by the NLP community, was a stark wake-up call for many in robotics.
Naturally, if you can't outpace your competition, the next best option is to join them. The intersection of robotics and LLMs could have been superficial—perhaps using a language model to converse with a robot or having it recite poetry in Klingon. However, the reality has proven to be a profound revelation: the connections between the two fields are far more intricate than anticipated, and we are only beginning to explore this depth.
It’s a common misconception that LLMs are solely about language. While language is indeed the primary medium they utilize (along with code), their true strength lies in commonsense reasoning. For instance, LLMs understand basic truths like "a book belongs on a shelf, not in a bathtub" or "the process of making coffee," which is crucial for embodied agents operating in the real world. Therefore, it’s unsurprising that the initial area of robotics to benefit from LLMs is planning.
To illustrate how a robot functions conceptually, consider this simplified model: a robot perceives its environment, relays that information to a planner, which, in conjunction with a defined goal, devises a plan to achieve it. This plan is then sent to a robot controller responsible for executing it through hardware actions. As the environment continuously changes, only the initial steps of the plan may be executed until the state is updated, prompting the robot to replan and continue executing.
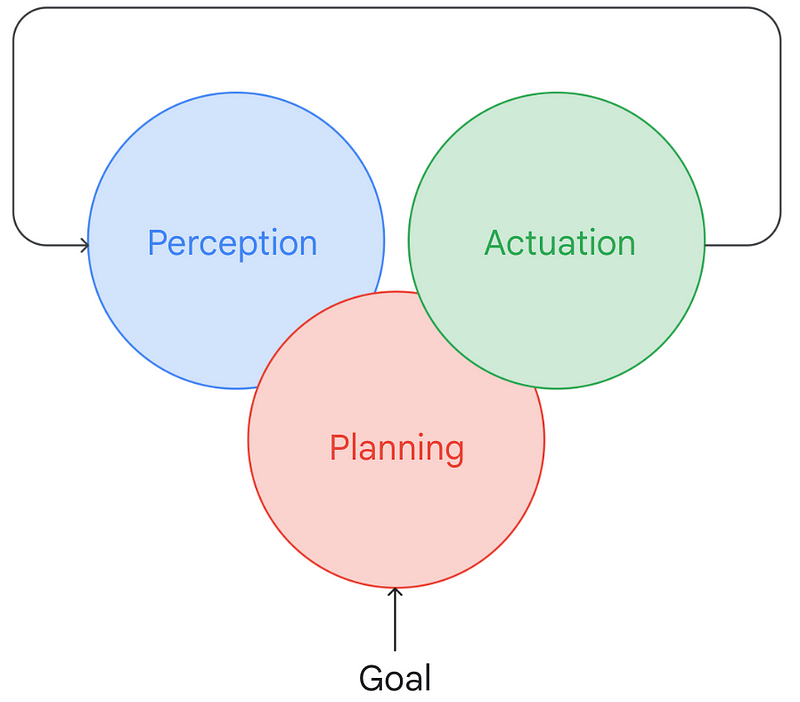
This basic model aligns with key subfields in robotics: state estimation, task and motion planning, and control. Traditionally, these areas have developed independently, often leading to systemic challenges being overlooked and issues being shuffled between disciplines. For instance, many TAMP (Task and Motion Planning) papers assume perfect state estimation, while numerous control strategies dismiss plans they cannot execute—don't even get me started on the difficulty of ensuring gradient flow across these boundaries!
Thus, the initial disruption occurred in planning. I may be biased, but I would highlight SayCan as a pivotal moment when the community recognized that by shifting much of the planning into "semantic space," rather than geometric space, we could leverage LLMs to enhance this process. This shift allows us to utilize the common-sense reasoning capabilities of LLMs without needing to gather extensive data, create robot-specific ontologies, or develop symbolic reasoning engines.
Once perception and actuation interfaces utilize natural language, it becomes increasingly tempting to adopt language as the universal API. Language offers numerous advantages: it is adaptable, interpretable, and capable of describing concepts at various levels of abstraction. The latter presents a significant challenge for fixed APIs; for instance, while it may suffice for a self-driving car to view its world as mere bounding boxes, when engaging with objects directly, richer geometry and semantics are essential. The planner may not always know in advance what information would be useful for the perception module, suggesting a need for a two-way dialogue.
This leads to the next phase of development: enabling both the planner and the perception system to communicate using natural language. With the advancements in visual language models (VLMs), we can harness them to facilitate a genuine dialogue between models. This notion is central to Socratic Models, where consensus about the state of the environment and the appropriate actions can be reached through model interactions. The concept of Inner Monologue extends this idea by integrating periodic state reestimation and replanning into the conversation.
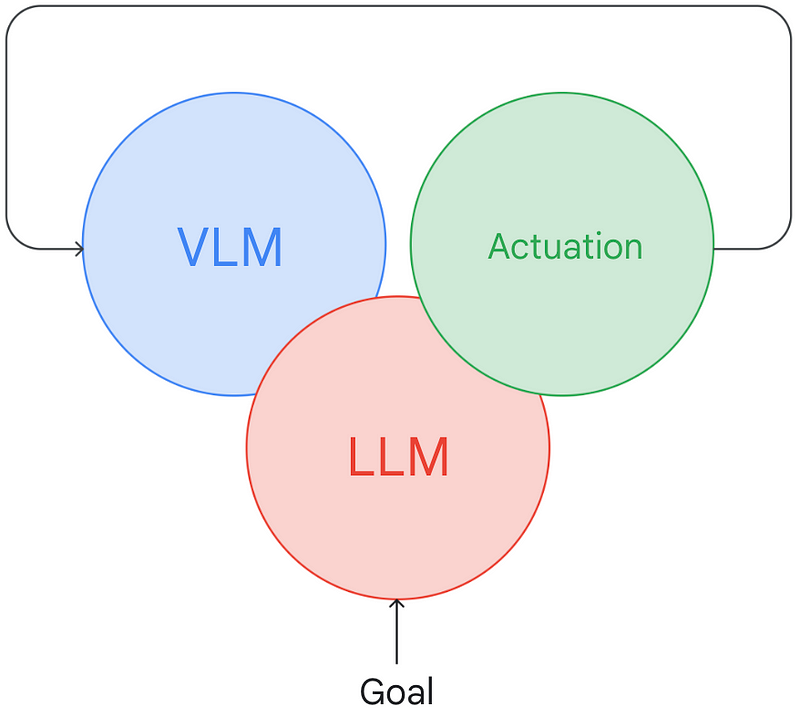
By incorporating an LLM into the core of robotic intelligence, a plethora of new possibilities arises. For example, with AutoRT, we utilized the LLM to generate new tasks for robots, which raised an important question: if robots can autonomously generate tasks, how do we ensure they are safe and beneficial? We can guide the LLM with specific safety concepts ("avoid sharp objects") or broader human-centered principles: "you must not harm a human." Sound familiar? Just a couple of years ago, if someone had suggested that we might have a feasible path to implementing Asimov's laws of robotics in a real robot, I would have found it hard to believe. Whether employing Constitutional AI as part of a robot's safety framework proves practical remains to be seen, but the mere fact that we can discuss and assess this in a real-world context is groundbreaking.
What about the actuation element? Can we also apply the LLM approach to this traditionally rigid aspect of robotics? LLMs excel at code generation, and at its essence, controller software is just a code-based description of a policy. This is where the idea of Code as Policies emerges, suggesting that we can prompt an LLM with low-level control APIs and allow it to articulate the policy needed for execution.
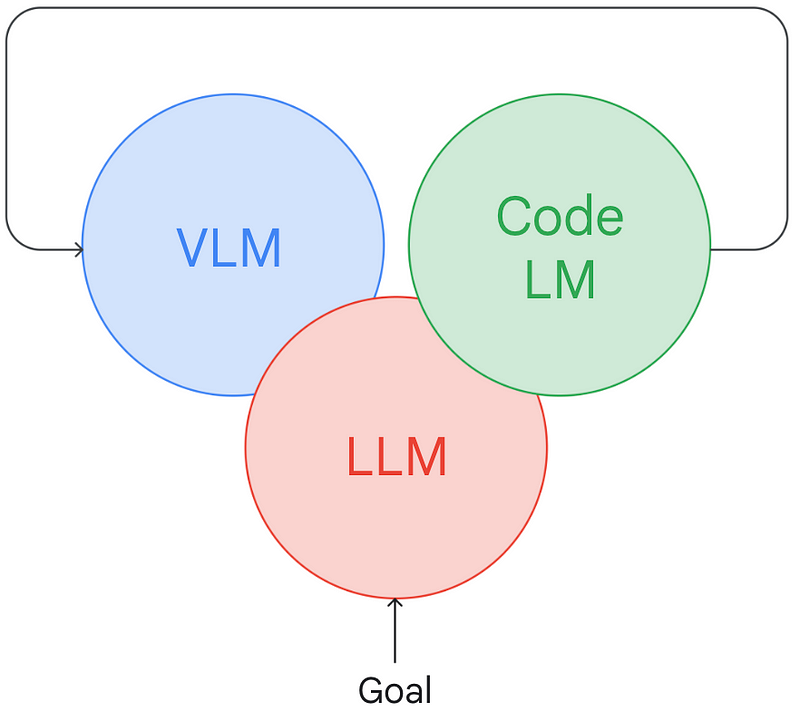
Code language models (Code LMs) perform this task effectively without prior training, as long as you have a good grasp of prompt design. Engaging in a dialog strategy to refine prompts has proven successful in early ChatGPT for Robotics experiments conducted by our colleagues at Microsoft. The results are even more promising when we can create a feedback loop to fine-tune our Code LM based on interactive prompting and the refinement of control behaviors. We refer to this method as Language Model Predictive Control, drawing parallels to traditional Model Predictive Control. This approach not only enhances performance on novel tasks but also accelerates learning from user interactions.
As we envision various LLMs communicating in an internal chat room at the core of a robot, it raises the question of whether maintaining distinct roles for the problem components remains beneficial. Neural networks can exchange information through high-bandwidth, differentiable representations; why limit communication to text? While some interpretability is gained, the loss of information can be substantial. Consider, for example, that if the planner remains oblivious to the environment, can we merge some components? This is not a pursuit of end-to-end zealotry, but rather an exploration of the inherent modularity present in these models, thanks to how different transformer components interact, allowing us to achieve a similar "separation of concerns" within the neural network itself.
The initial experiment in this realm sought to integrate perception and planning using PaLM-E.
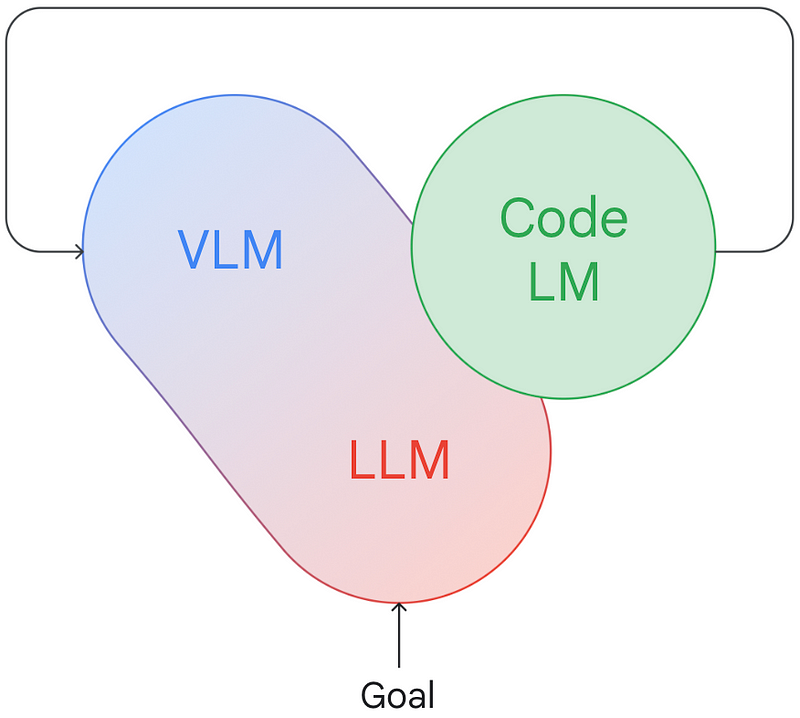
This integration yielded remarkable results, demonstrating clear improvements from the joint training of perception and planning modules, along with evidence of knowledge transfer across tasks and embodiments.
The next step was to merge perception and actuation while excluding the planner, which needs to be sufficiently large to be effective. Numerous studies have explored "pixels to action" models, but we found that RT-1 represented a transformative approach. Recent months have seen an explosion of advancements in this field, with initiatives like Action Diffusion from TRI, Humanoid Transformer from Berkeley, ACT, and Octo from Stanford leading to significant improvements in performance and capabilities.
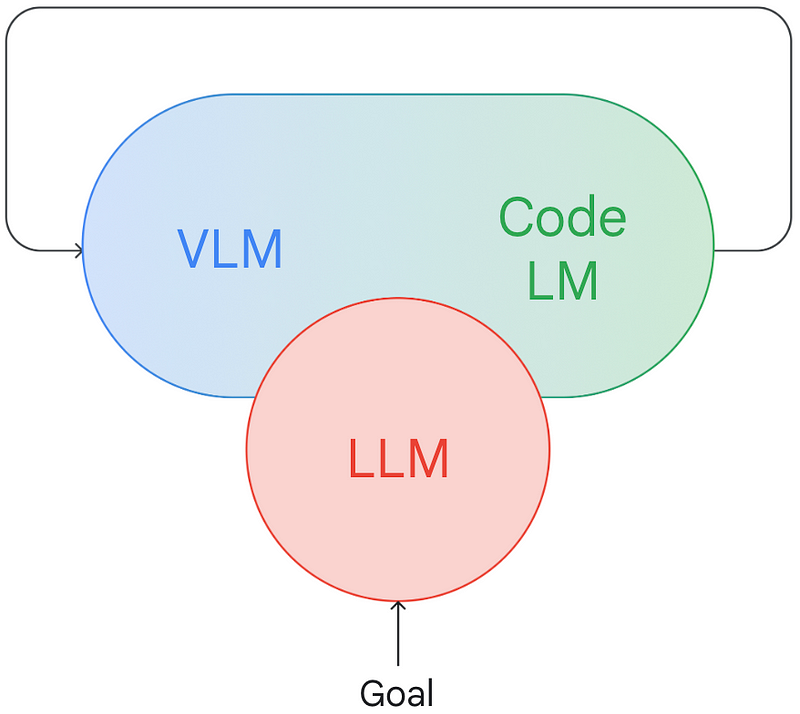
At this point, it’s clear where this trajectory is heading: rather than settling for partial solutions, why not develop a comprehensive “robot brain” that encompasses all functionalities? Our initial attempt in this direction was RT-2, which convincingly demonstrated the benefits of joint reasoning across the entire problem, while still utilizing non-robotics data sources (particularly for perception and semantic understanding). VC-1, developed by our colleagues at Meta, marks another significant step in this direction. I anticipate even more developments in the near future, as the open-source landscape for multimodal models flourishes and researchers explore the limits of these models’ spatial reasoning capabilities.
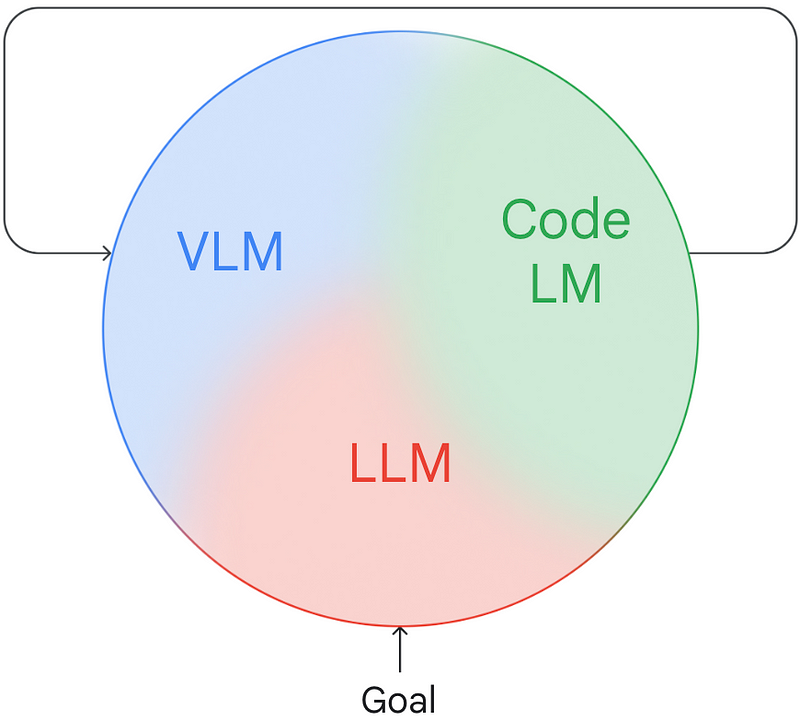
What lies ahead? The semi-supervised revolution has passed, and reinforcement learning is still recovering, as diffusion models continue to challenge its dominance and offline RL makes a resurgence. Despite notable enhancements in data efficiency, which allow for operations in the real world rather than relying solely on simulation-to-reality strategies, we remain constrained by data limitations. Enhancing the efficiency and diversity of data collection is crucial.
A significant tension within the field today revolves around two contrasting approaches: on one hand, the effectiveness of cross-embodied models in transferring capabilities across different robots suggests a need for increased variety in robots and tasks, advocating for a diversity-centered approach. On the other hand, there is a strong push for a "one embodiment to rule them all" philosophy in robot learning, with billions of dollars being invested in versatile robots such as Tesla, Figure, 1X, Agility, Unitree, Sanctuary, Apptronik, and more. The advantage of this latter strategy is the universal capabilities that are well-suited for learning from human interactions and operating within human environments. However, the downside is the complexity and cost of constructing, deploying, and maintaining sophisticated hardware, which significantly impacts the feasibility of scaling data collection.
This presents a considerable risk, especially if the cross-embodiment hypothesis holds true. The emergence of numerous low-cost robots, as demonstrated by initiatives like Aloha, UMI, Stretch (and Dobb.E), Mobile Aloha, and Aloha 2, could fundamentally disrupt the field, making dexterous capabilities accessible across a wide range of affordable embodiments. Nevertheless, I would hesitate to fully commit to either side of this debate at this juncture: the upcoming months will be pivotal in determining the future direction of the field, whether it favors diversity or universality, inexpensive and agile solutions versus high-DOF and feature-rich designs. Currently, we find ourselves in a hybrid state: while "universal" robotic arms are prevalent, the economics of deploying them can be daunting, often necessitating customized tooling and systems integration to render them truly functional.
One belief I am forming regarding data scaling is that generative models represent the future of simulation. Instead of merely seeking "better simulators," we should aim to develop generative 3D and video models that respect not only visual fidelity but also physics and spatial relationships. Other sectors of physics simulation, from weather prediction to protein folding, are being transformed by generative models. If I could capture my robot's sensory input and simply hit "play" to generate potential future scenarios, as we explored in Video Language Planning, we could simultaneously address both the "sim-to-real" challenge and the scene authoring dilemma.
Additionally, I am increasingly convinced that data scaling is evolving into a human-robot interaction (HRI) challenge—not necessarily the specific issues currently prioritized by the HRI community, which predominantly focuses on end-user interactions with robots. We require improved HRI strategies for designing diverse tasks, efficiently gathering data, and refining behaviors. Streamlining the meticulous design required for effective data collection to train models, even before end-users engage with the final product, is essential. The HRI community now has a unique opportunity to innovate, essentially transforming every robot into a chatbot with sensory and motor capabilities.