Avoid Common Mistakes When Scraping Websites for Data
Written on
Understanding Web Scraping Essentials
When it comes to scraping websites, many individuals aspire to achieve speed, efficiency, and reliability. However, it's easy to fall into traps that hinder the performance of your scraper. Rather than just completing the task, aim to create a robust scraper that consistently delivers dependable data quickly. Below are critical missteps to avoid when scraping.
Section 1.1 Choosing the Right Tool
One major mistake is limiting yourself to a single scraping tool. It's surprising how many people persist with one tool, even when an alternative could simplify the task. Ensure you don’t become one of them!
When scraping, remember that you have an array of tools at your disposal. Select the one that aligns best with the specifics of your project.
For instance, if you are utilizing Python, you might consider libraries like Beautiful Soup, Selenium, or Scrapy. Each of these tools excels in different scenarios, so your choice should reflect your project’s needs—be it speed, scalability, or simplicity.
If your goal is merely to extract data from HTML or XML files, Beautiful Soup can accomplish that in no time. Why complicate things by building a spider with Scrapy if you don't need its advanced features? For a deeper understanding of these libraries, check out my comprehensive guide.
Section 1.2 Managing Request Frequency
Another common error is bombarding the target website with too many requests in a short span. While it may seem efficient to use a for loop for scraping, this can inadvertently lead to overwhelming the server with traffic, potentially causing downtime.
To illustrate, consider this typical approach:
for link in links:
If you have thousands of links, you're sending out just as many requests in rapid succession. This can be harmful, as it may lead to server overload.
To mitigate this, incorporate delays between requests:
import time
for link in links:
time.sleep(4)
Tools like Selenium also offer explicit waits that can adjust based on the conditions being monitored.
The first video titled Don't Start Web Scraping without Doing These First discusses fundamental practices to set a solid foundation for web scraping.
Section 1.3 Embracing Asynchronous Requests
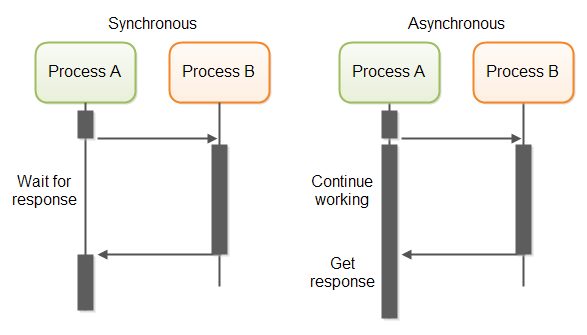
If you find your scraper is slow, it might be due to over-reliance on synchronous requests. While synchronous programming is straightforward, it can significantly slow down your scraping process.
In synchronous programming, each line of code runs sequentially. Conversely, asynchronous programming allows your code to process multiple requests concurrently.
Imagine needing to scrape 1000 links: with synchronous requests, each request must wait for the previous one to complete. However, with asynchronous requests, you can work on multiple links simultaneously, greatly improving efficiency.
Section 1.4 Avoiding Login Data Scraping
Be cautious when attempting to scrape data that resides behind a login. Many websites employ anti-scraping measures that complicate this process.
Scraping through a login can easily lead to account bans rather than IP bans, especially if you're violating the site's terms of service. It’s advisable to steer clear of this practice and focus on publicly accessible data.
Section 1.5 Preparing for the Unexpected
Even after successfully developing a scraper, it’s crucial to ask, "What if...?" Websites are constantly evolving, which can create new challenges for scraping.
Here are some questions to consider:
- What if my IP gets blocked?
- What if the internet connection is slow?
- What if I encounter a CAPTCHA?
- What if the page layout changes?
Anticipate these issues and build mechanisms to handle potential failures.
Section 1.6 Considering API Availability
Lastly, before opting for web scraping, check if the website offers an API. Many sites provide APIs that simplify data extraction.
While not all sites have APIs, utilizing one can save you time and reduce complications. If no API exists, ensure you review the website's terms and the robots.txt file to understand the scraping permissions.
For instance, here’s a sample snippet from Amazon's robots.txt file:
User-agent: *
Disallow: /exec/obidos/account-access-login
Disallow: /exec/obidos/change-style
Allow: /wishlist/universal*
Allow: /wishlist/vendor-button*
By avoiding these common pitfalls, you can enhance your web scraping endeavors.
The second video titled The Biggest Issues I've Faced Web Scraping (and how to fix them) offers insights into common challenges and their solutions in web scraping.